Vitesse DB is a PostgreSQL OLAP solution, designed for data mart and data warehouse workload. To validate the performance of Vitesse DB Enterprise Edition under such workloads, we measured using the Transaction Processing Performance Council’s TPC-H benchmark at scale factor 100.
All 22 queries of TPC-H are measured against vanilla PostgreSQL and Vitesse DB Enterprise Edition using both row and column stores. We call out Q1 and Q5 specifically because they are rather common in a data warehouse environment.
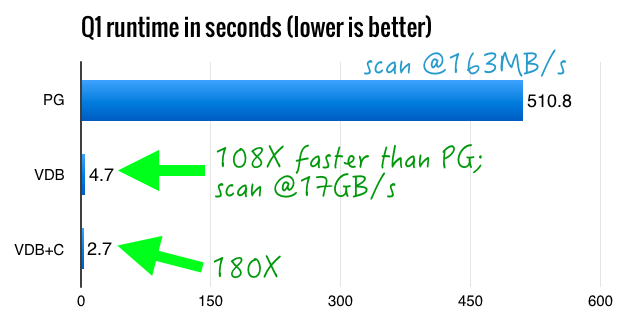
Scan and agg on 81 GB table can be done in 5 seconds.
Q1 is a typical aggregate query running against the fact table. In
this case, the fact table lineitem has 600 million
rows and occupies 81GB on disk. Q1 scans the table and produce
4 sums, 3 averages, and 1 count aggregates. Note that the filter
only disqualifies ~2% of the rows in the table.
SELECT lineitem.l_returnflag,
lineitem.l_linestatus,
sum(lineitem.l_quantity) AS sum_qty,
sum(lineitem.l_extendedprice) AS sum_base_price,
sum(lineitem.l_extendedprice * (1 - lineitem.l_discount)) AS sum_disc_price,
sum(lineitem.l_extendedprice * (1 - lineitem.l_discount) * (1 + lineitem.l_tax)) AS sum_charge,
avg(lineitem.l_quantity) AS avg_qty,
avg(lineitem.l_extendedprice) AS avg_price,
avg(lineitem.l_discount) AS avg_disc,
count(*) AS count_order
FROM lineitem
WHERE lineitem.l_shipdate <= ('1998-12-01'::date - '112 days'::interval)
GROUP BY lineitem.l_returnflag, lineitem.l_linestatus;
6-way-join involving 100 GB of data can be done in 12 seconds.
Q5 is an aggregate over a snowflakey 6-way hashjoin that joins the fact table
lineitem table against the
orders and supplier tables, and
subsequently against other dimension tables.

SELECT nation.n_name,
sum(lineitem.l_extendedprice * (1 - lineitem.l_discount)) AS revenue
FROM customer, orders, lineitem, supplier, nation, region
WHERE customer.c_custkey = orders.o_custkey
AND lineitem.l_orderkey = orders.o_orderkey
AND lineitem.l_suppkey = supplier.s_suppkey
AND customer.c_nationkey = supplier.s_nationkey
AND supplier.s_nationkey = nation.n_nationkey
AND nation.n_regionkey = region.r_regionkey
AND region.r_name = 'AMERICA'
AND orders.o_orderdate >= '1994-01-01'
AND orders.o_orderdate < ('1994-01-01'::date + '1 year'::interval)
GROUP BY nation.n_name;
Raw result: PG vs Vitesse DB using Heap Tables
Q PG VDB-Row Speedup 1 510.8 4.7 108.5 2 98.5 6.2 15.8 3 296.8 20.7 14.3 4 408.9 26.9 15.2 5 320.7 11.6 27.5 6 122.5 5.0 24.7 7 732.0 42.3 17.3 8 288.1 14.1 20.4 9 10000.0 102.8 97.3 10 355.1 49.1 7.2 11 60.2 4.4 13.8 12 186.9 21.9 8.6 13 275.4 24.1 11.4 14 128.2 9.1 14.1 15 251.3 12.7 19.8 16 54.0 6.1 8.9 17 688.2 66.8 10.3 18 540.2 34.4 15.7 19 169.9 9.5 17.9 20 318.5 26.1 12.2 21 10000.0 96.5 103.6 22 107.7 13.1 8.2
Raw result: PG vs Vitesse DB using Column Store
Q PG VDB-Col Speedup
1 510.8 2.7 189.8
2 98.5 5.4 18.3
3 296.8 20.3 14.7
4 408.9 28.0 14.6
5 320.7 10.4 30.7
6 122.5 1.1 110.4
7 732.0 57.1 12.8
8 288.1 6.7 43.1
9 10000.0 105.9 94.4
10 355.1 45.7 7.8
11 60.2 2.9 21.0
12 186.9 19.8 9.4
13 275.4 23.9 11.5
14 128.2 5.8 22.2
15 251.3 8.7 28.8
16 54.0 5.5 9.8
17 688.2 64.5 10.7
18 540.2 35.4 15.2
19 169.9 9.0 18.9
20 318.5 25.9 12.3
21 10000.0 97.9 102.2
22 107.7 13.7 7.8
- Machine
- Single HP ProLiant DL380.
- CPU
- 2 count Intel® Xeon® CPU E5-2670 @ 2.60GHz, 8-core, 20MB-cache.
- Memory
- 256GB.
- DLL Modifications
-
- Changed CHAR(1) types to Postgres ENUM type.
- Changed NUMERIC type where appropriate to MONEY type.
- Changed NUMERIC type where appropriate to DOUBLE PRECISION.
Note that it is not exactly fair to compare Vitesse DB Enterprise Edition against PostgreSQL. This is because Vitesse DB is able to fully employ all 16 cores on the machine, while PostgreSQL is only able to utilize a single core, leaving the other 15 idle. In an OLTP environment, one could argue that the idle cores would be consumed by other transactions. In an OLAP environment, however, there usually are not many concurrent transactions, and it would be unwise to underuse hardware.
In addition to using more cores, Vitesse DB runs a lot more efficiently in each core due to its LLVM JIT and data path optimization technologies. In concert, these techniques are well suited for OLAP workload and the result speaks for itself.